In the world of technology, we're witnessing a profound shift in how we interact with data. For decades, the gateway to a database has been Structured Query Language (SQL). Now, with the rise of Large Language Models (LLMs), the new language of data is natural language itself.
This shift promises a powerful, democratized future. Imagine a world where anyone could simply ask a question and receive a perfectly executed query. This is the vision of Text-to-SQL and Generative Business Intelligence (Gen-BI).
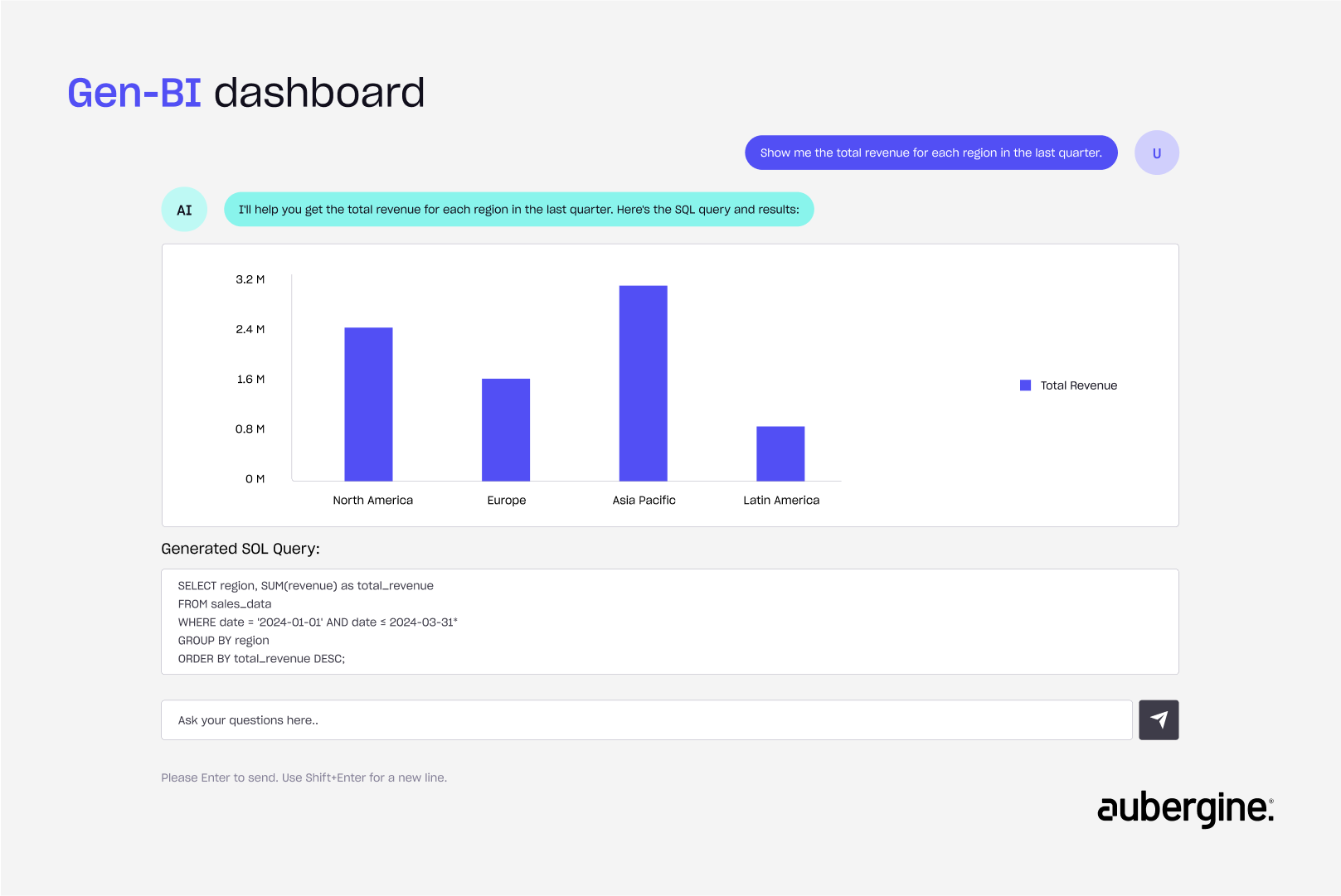
However, a significant problem persists. For business-critical applications, the accuracy of these Text-to-SQL models is often not good enough. Queries generated from natural language by LLMs can be riddled with errors, returning incorrect data or failing entirely.
So, where does the issue lie? The core problem isn't just with the LLM database, but with us also. We have been designing databases for humans, not for machines. Our schemas are filled with shorthand, jargon, and implicit context that a human developer can understand, but an AI model cannot.
This blog will explore how to fix this fundamental disconnect. This re-evaluation is not just about the database; it's a cascading effect across the entire stack, from frontend design to backend architecture. The true power of Text-to-SQL can only be unlocked when the database itself is built to be understood by the machines we're asking to understand us.
Core Challenges: The disconnect between design and clarity
Text-to-SQL Benchmarks like BIRD (a popular dataset to evaluate LLMs on real-world SQL generation tasks) show that even the best models with proper training and fine tuning today is able to achieve ~75% accuracy. That means 1 in every 4 queries is wrong — which is a dealbreaker for business-critical apps. This shift demands a rethinking of how we design our databases. How do we structure schema, table names, relationships, and metadata so that LLMs can understand and reason over them? That’s exactly what we’ll explore in this blog for SQL database.
Core bottleneck: Schema ≠ semantics
You might think:
“If we just pass the full database schema as context to the LLM and ask to generate a SQL query, it should work, right?”
Not Really. Even with access to table names, column names, and relationships, LLMs often fail to generate correct SQL queries. Why?
Passing raw table/column names (or even a full ER diagram) to an LLM database is not enough; if names are vague or shorthand, the model has no concept of the underlying business meaning.
Because in most real-world schemas, table and column names are not self-explanatory. They don’t convey enough meaning for LLMs to reason over.
And let’s be honest. Sometimes, even developers struggle to understand these schemas, so we can’t expect AI to understand them either.
Case Example: Common schema design issues
Here are common mistakes that break LLM database reasoning — and how we developers intentionally or unintentionally create them:
1. Ambiguous or vague field names
A customer asks, “What are the names of our most popular products?” The LLM scans the products table but finds columns named item_name, prod_title, and p_desc. It doesn’t know which one represents the "name." This inconsistency forces it to guess, leading to an incorrect or failed query. A human knows that p_code is the product code, but an LLM sees only an arbitrary string.
2. Custom terminologies
AI doesn’t know internal business metrics or naming logic. These terms are meaningless to an LLM without an explicit definition of what they represent and how they are calculated. These custom terminologies are often derived metrics or computed fields that aren’t stored directly in the database, but are the result of applying formulas or logic across multiple columns and tables.
Every business has its own KPIs, jargon, or naming conventions that make sense internally but are meaningless to an LLM without definitions.
Let’s say your business defines the following terms like:
1. Golden Product: A product that was sold at least 50 times in the last 30 days with a return rate below 2%.
2. Churn Risk Score: A score from 0 to 1 representing the likelihood to churn, based on last activity, support tickets, and NPS.
3. Returning Customer: A customer who has made purchases in at least two different months
These concepts aren’t stored as columns in your database they’re derived metrics, computed using business logic across multiple tables.
Since LLMs can’t guess your definitions, they’ll either hallucinate or fail to generate the right query.
Tip: we can store the computational metric in SQL Views, Materialised Views or store definition in the schema_metadata table
3. Inconsistent data formats
One column stores a join_date as "2025-07-13", another has order_date as "13/07/2023", and a third column created_at uses "2025-07-13T14:35:20Z” ,
Without clear consistency, it requires explicit instructions or conversion rules in LLM propts to explain how to standardise the values before building the correct query.
4. Unclear relationships
The database has an orders table and a products table, connected by a junction table called order_items. A human knows this table links the two, but to an LLM, the table name alone doesn't clearly define its purpose. It might struggle to join these tables correctly to answer a question like, "Which products were included in order #1234?"
5. Enum fields without context
The orders table includes a status column with values like 1, 2, and 3. To a developer, these codes are well-known: 1 = pending, 2 = shipped, 3 = delivered. To the LLM, they are just numbers, making it impossible to answer a question like, “How many orders are still pending?”
The rationale behind current practices
To truly understand why our databases are not "AI-ready," we must first acknowledge the context in which they were built. The design choices that now impede LLMs weren't made out of negligence; they were a result of very real constraints and priorities.
1. Shorter names for productivity
Writing long descriptive field names like project_assignment_start_date over and over is painful in SQL and code. So we go with a shorter name like proj_asgn_start.
2. Team knowledge sharing
In practice, many databases are designed around team context.
We rely on:
- Internal documentation
- Conventions passed down during onboarding
- “Ask that one dev who knows it”
This works fine within the team, but LLMs don’t get access to that tribal knowledge. All they see is the raw schema — and that’s rarely enough.
3. Optimization over readability
Denormalizing or using compressed field names helps with performance or legacy system constraints. These are valid engineering decisions, but they make the schema harder to reason about semantically.
This understanding is critical. Our current database designs are a product of their time, optimized for human collaboration and system performance. The challenge now is to evolve these practices to support a new type of user: the AI agent.
Possible Solutions: A new AI-First database design protocol
What we truly need is an MCP-style standard — a machine-comprehensible protocol, but for databases, where AI-friendliness is baked into schema design from the ground up.
Such protocol could define:
- Naming conventions
- Structured metadata
- Semantic linking
- Machine-readable descriptions
- Domain ontology integration
Until such formal protocol emerges, there are practical steps teams can take today to move in that direction.
1. Introducing a semantic layer
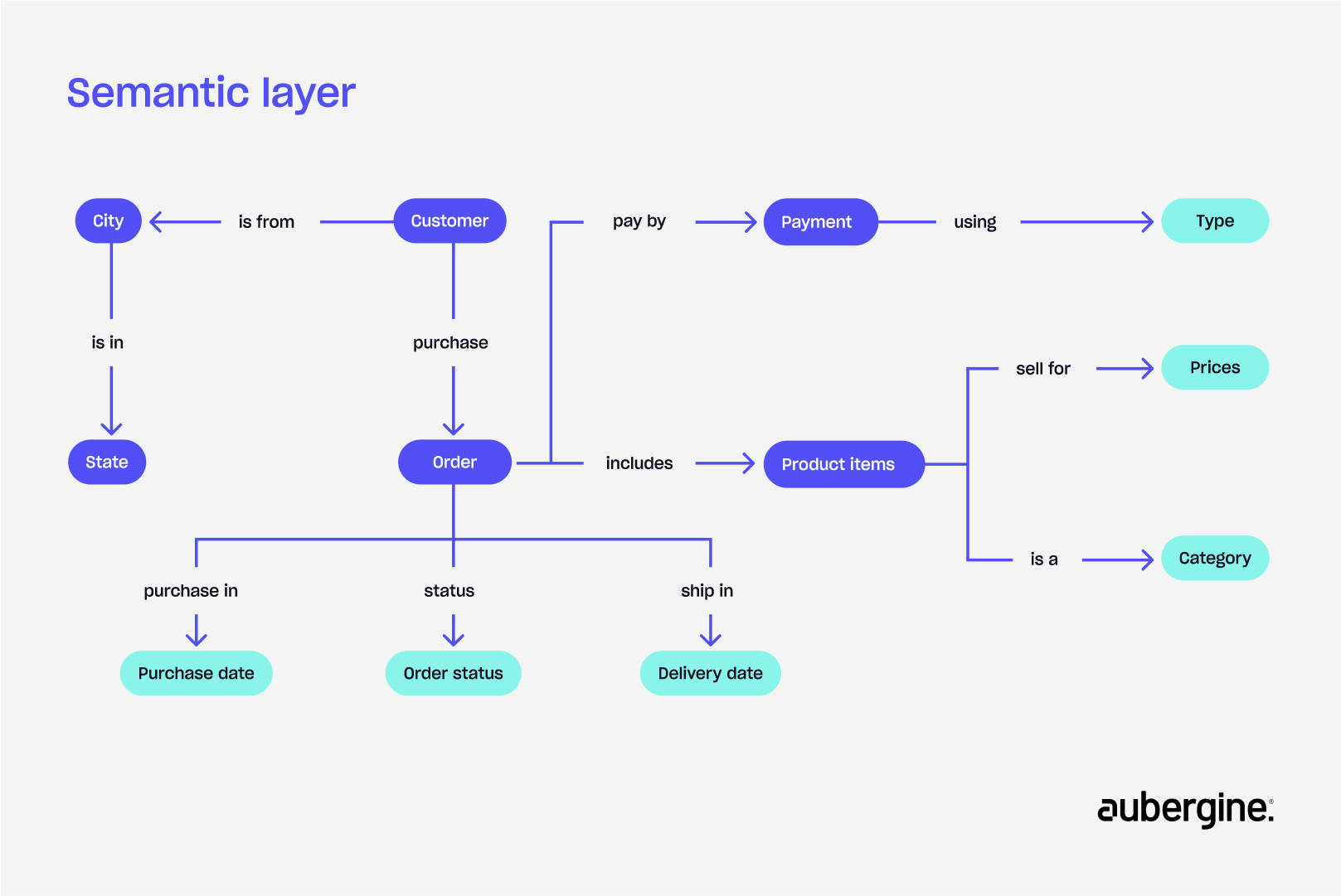
A semantic layer acts as a bridge between natural language and raw database structure.
Instead of just storing raw data, you define:
- Entities(Who or what the data is about): Customer, Invoice, Region
- Metrics(What you want to measure): total_sales, average_order_value
- Relationships(How things connect): “Each customer has many orders”, “Products belong to categories”
You also enrich tables and columns with descriptions, units, mappings, and examples:
order_status:
description: "'C' = Completed, 'P' = Pending, 'X' = Cancelled"
data_type: string
sample_values: ['C', 'P', 'X']This makes it easier for LLMs to reason not just about what data exists, but what it means.
Tools like Cube.dev and Wren.ai provide frameworks to encode these semantics.
2. Enhancing schema naming and documentation standards
Before even implementing a semantic layer, we can make significant improvements at the database level. The goal is to move from cryptic shorthand to clear, descriptive names. For example, instead of cust_tbl, use customers. Instead of dob, use date_of_birth.
Many databases like PostgreSQL, BigQuery, Snowflake, and SQL Server support a COMMENT or DESCRIPTION feature that lets you attach human-readable descriptions to tables and columns directly within the schema. These comments can serve as semantic hints for LLMs — making it easier for them to understand the meaning behind vague or technical field names.
Furthermore, creating centralized metadata tables within the database can provide in-line documentation. These tables can contain descriptive text for each column, explaining its purpose, data type, and any business logic associated with it. This practice makes the schema self-documenting and provides a rich source of truth for an LLM to learn from.
3. Implementing retrieval-augmented generation (RAG) for contextual understanding
A powerful way to provide real-time context to an LLM is by using Retrieval-Augmented Generation (RAG). RAG can dynamically fetch relevant schema definitions, metadata, or even example queries from a knowledge base and inject them into the LLM's prompt.
When a user asks a question, the system can retrieve the most relevant table and column descriptions, effectively "reminding" the LLM of the necessary context before it generates the SQL. This approach dramatically improves accuracy by providing the LLM with up-to-the-minute information about the schema.
We can also fine-tune the model on your schema and business logic, but that’s usually better when your schema is stable and doesn’t change frequently
4. Leveraging AI for schema co-design and validation
Finally, we can turn the tables and use AI to help us design better schemas in the first place. LLMs can be used to analyze existing schemas, identify ambiguous naming conventions, and suggest more descriptive alternatives.
They can also be used to validate schema structures by attempting to generate queries and highlighting areas where they struggle. This co-design process allows us to build schemas that are inherently more "legible" to both humans and machines, future-proofing our data infrastructure.
Strategic considerations: Future-proofing data infrastructure
Building LLM-compatible database schemas isn't just about a one-time technical fix; it’s a strategic decision that future-proofs your entire data infrastructure. In an era where AI is becoming the primary interface for data, adapting now is a competitive necessity.
Adapting to the AI-first future
The fundamental shift from code-based queries to natural language access means that your data's long-term relevance depends on its legibility to AI. A rigid, human-centric database schema will become a liability, locking your business into slow, manual data analysis processes.
By adopting AI-compatible schema designs, you are ensuring your data can be easily integrated with new AI tools and models as they emerge, from generative analytics platforms to autonomous agents that can execute complex tasks without human intervention. This proactive approach ensures your business remains agile and relevant in a rapidly evolving technological landscape.
Gaining a competitive advantage
Early adoption of AI-ready database structures provides a significant competitive edge. While your competitors are still struggling with the accuracy problem and relying on specialized data teams, your organization can already be democratizing data access.
This allows for faster decision-making, as insights that once took days to generate can be delivered in seconds. It also frees up your data scientists and engineers to work on high-value, complex problems instead of routine data requests, accelerating innovation and growth.
Ensuring scalability and flexibility
Structuring databases for LLM compatibility isn't just about making them understandable; it's also about making them more robust and flexible. By adding rich metadata layers and clear naming conventions, you create a self-documenting system that simplifies onboarding for new team members and makes it easier to scale your infrastructure.
This foundational clarity reduces data redundancy, streamlines maintenance, and ensures that your database can grow and adapt to new business needs without becoming a tangled mess of siloed, poorly defined data.
Conclusion
The challenge is clear: traditional databases were designed for developers, not for AI models. The shortcuts and implicit knowledge that made them efficient for human teams are the very things that hinder our ability to leverage the power of Text-to-SQL.
However, the path forward is also clear. The solution lies not in waiting for LLMs to become flawless, but in actively building our data infrastructure to meet them halfway. This is achieved by:
- Adopting clear, consistent naming conventions: Moving from cust_id to customer_id and ensuring every field is immediately understandable.
- Normalizing data and reflecting relationships accurately: Creating clean, well-defined relationships between tables.
- Adding rich metadata layers for semantic clarity: Building a business-friendly semantic layer that provides explicit definitions for entities and metrics.=
- Leveraging RAG for contextual query generation: Using external context to augment LLM queries and improve accuracy.
- Involving LLMs in schema co-design: Using AI to help build and validate schemas that are inherently more legible to both humans and machines.
Our long-term vision must be to build databases for future AI interactions, facilitating a world where natural language is the universal gateway to data. By taking these strategic steps now, we don’t just fix today's problems—we future-proof our data infrastructure and unlock a new era of AI-driven productivity and innovation. Partner with us to start building your AI-ready database today.


Authors